

Crawl funds is a crucial web optimization idea for giant web sites with millions of pages or medium-sized web sites with a number of thousand pages that change every day.
An instance of a web site with hundreds of thousands of pages could be eBay.com, and web sites with tens of hundreds of pages that replace often could be person critiques and score web sites much like Gamespot.com.
There are such a lot of tasks and points an web optimization knowledgeable has to contemplate that crawling is commonly placed on the again burner.
However crawl funds can and must be optimized.
On this article, you’ll be taught:
- The right way to enhance your crawl funds alongside the best way.
- Go over the adjustments to crawl funds as an idea within the final couple of years.
(Notice: In case you have a web site with just some hundred pages, and pages aren’t listed, we advocate studying our article on frequent issues causing indexing problems, as it’s definitely not due to crawl funds.)
What Is Crawl Funds?
Crawl funds refers back to the variety of pages that search engine crawlers (i.e., spiders and bots) go to inside a sure timeframe.
There are particular concerns that go into crawl funds, akin to a tentative balance between Googlebot’s makes an attempt to not overload your server and Google’s general want to crawl your area.
Crawl funds optimization is a collection of steps you’ll be able to take to extend effectivity and the speed at which serps’ bots go to your pages.
Why Is Crawl Funds Optimization Necessary?
Crawling is step one to showing in search. With out being crawled, new pages and web page updates gained’t be added to go looking engine indexes.
The extra typically that crawlers go to your pages, the faster updates and new pages seem within the index. Consequently, your optimization efforts will take much less time to take maintain and begin affecting your rankings.
Google’s index comprises hundreds of billions of pages and is rising every day. It prices serps to crawl every URL, and with the rising variety of web sites, they need to cut back computational and storage prices by reducing the crawl rate and indexation of URLs.
There may be additionally a rising urgency to cut back carbon emissions for local weather change, and Google has a long-term technique to enhance sustainability and reduce carbon emissions.
These priorities might make it tough for web sites to be crawled successfully sooner or later. Whereas crawl funds isn’t one thing it’s good to fear about with small web sites with a number of hundred pages, useful resource administration turns into an essential challenge for large web sites. Optimizing crawl funds means having Google crawl your web site by spending as few sources as doable.
So, let’s talk about how one can optimize your crawl funds in as we speak’s world.
1. Disallow Crawling Of Motion URLs In Robots.Txt
You could be stunned, however Google has confirmed that disallowing URLs will not affect your crawl budget. This means Google will nonetheless crawl your web site on the similar charge. So why will we talk about it right here?
Properly, when you disallow URLs that aren’t essential, you principally inform Google to crawl helpful components of your web site at a better charge.
For instance, in case your web site has an inner search characteristic with question parameters like /?q=google, Google will crawl these URLs if they’re linked from someplace.
Equally, in an e-commerce website, you may need aspect filters producing URLs like /?shade=purple&dimension=s.
These question string parameters can create an infinite variety of distinctive URL combos that Google might attempt to crawl.
These URLs principally don’t have distinctive content material and simply filter the info you’ve, which is nice for person expertise however not for Googlebot.
Permitting Google to crawl these URLs wastes crawl funds and impacts your web site’s general crawlability. By blocking them through robots.txt guidelines, Google will focus its crawl efforts on extra helpful pages in your website.
Right here is how you can block inner search, aspects, or any URLs containing question strings through robots.txt:
Disallow: *?*s=*
Disallow: *?*shade=*
Disallow: *?*dimension=*
Every rule disallows any URL containing the respective question parameter, no matter different parameters which may be current.
- * (asterisk) matches any sequence of characters (together with none).
- ? (Query Mark): Signifies the start of a question string.
- =*: Matches the = signal and any subsequent characters.
This strategy helps keep away from redundancy and ensures that URLs with these particular question parameters are blocked from being crawled by serps.
Notice, nevertheless, that this technique ensures any URLs containing the indicated characters will likely be disallowed irrespective of the place the characters seem. This will result in unintended disallows. For instance, question parameters containing a single character will disallow any URLs containing that character no matter the place it seems. If you happen to disallow ‘s’, URLs containing ‘/?pages=2’ will likely be blocked as a result of *?*s= matches additionally ‘?pages=’. If you wish to disallow URLs with a selected single character, you need to use a mixture of guidelines:
Disallow: *?s=*
Disallow: *&s=*The crucial change is that there is no such thing as a asterisk ‘*’ between the ‘?’ and ‘s’ characters. This technique permits you to disallow particular actual ‘s’ parameters in URLs, however you’ll want so as to add every variation individually.
Apply these guidelines to your particular use instances for any URLs that don’t present distinctive content material. For instance, in case you’ve wishlist buttons with “?add_to_wishlist=1” URLs, it’s good to disallow them by the rule:
Disallow: /*?*add_to_wishlist=*This can be a no-brainer and a pure first and most essential step recommended by Google.
An instance under exhibits how blocking these parameters helped to cut back the crawling of pages with question strings. Google was making an attempt to crawl tens of hundreds of URLs with totally different parameter values that didn’t make sense, resulting in non-existent pages.
Diminished crawl charge of URLs with parameters after blocking through robots.txt.
Nevertheless, generally disallowed URLs may nonetheless be crawled and listed by serps. This will appear unusual, nevertheless it isn’t typically trigger for alarm. It often signifies that different web sites hyperlink to these URLs.
Google confirmed that the crawling exercise will drop over time in these instances.
 Google’s touch upon Reddit, July 2024
Google’s touch upon Reddit, July 2024One other essential advantage of blocking these URLs through robots.txt is saving your server sources. When a URL comprises parameters that point out the presence of dynamic content material, requests will go to the server instead of the cache. This will increase the load in your server with each web page crawled.
Please keep in mind to not use “noindex meta tag” for blocking since Googlebot has to carry out a request to see the meta tag or HTTP response code, losing crawl funds.
1.2. Disallow Unimportant Useful resource URLs In Robots.txt
Moreover disallowing motion URLs, it’s possible you’ll need to disallow JavaScript recordsdata that aren’t a part of the web site structure or rendering.
For instance, in case you have JavaScript recordsdata liable for opening pictures in a popup when customers click on, you’ll be able to disallow them in robots.txt so Google doesn’t waste funds crawling them.
Right here is an instance of the disallow rule of JavaScript file:
Disallow: /belongings/js/popup.js
Nevertheless, it is best to by no means disallow sources which are a part of rendering. For instance, in case your content material is dynamically loaded through JavaScript, Google must crawl the JS recordsdata to index the content material they load.
One other instance is REST API endpoints for type submissions. Say you’ve a type with motion URL “/rest-api/form-submissions/”.
Probably, Google might crawl them. These URLs are on no account associated to rendering, and it will be good observe to dam them.
Disallow: /rest-api/form-submissions/
Nevertheless, headless CMSs typically use REST APIs to load content material dynamically, so be sure you don’t block these endpoints.
In a nutshell, take a look at no matter isn’t associated to rendering and block them.
2. Watch Out For Redirect Chains
Redirect chains happen when a number of URLs redirect to different URLs that additionally redirect. If this goes on for too lengthy, crawlers might abandon the chain earlier than reaching the ultimate vacation spot.
URL 1 redirects to URL 2, which directs to URL 3, and so forth. Chains may also take the type of infinite loops when URLs redirect to 1 one other.
Avoiding these is a commonsense strategy to web site well being.
Ideally, you’d be capable to keep away from having even a single redirect chain in your complete area.
However it could be an not possible job for a big web site – 301 and 302 redirects are sure to seem, and you may’t repair redirects from inbound backlinks merely since you don’t have management over exterior web sites.
One or two redirects right here and there may not harm a lot, however lengthy chains and loops can turn into problematic.
As a way to troubleshoot redirect chains you need to use one of many web optimization instruments like Screaming Frog, Lumar, or Oncrawl to seek out chains.
Once you uncover a series, one of the best ways to repair it’s to take away all of the URLs between the primary web page and the ultimate web page. In case you have a series that passes by means of seven pages, then redirect the primary URL on to the seventh.
One other nice solution to cut back redirect chains is to switch inner URLs that redirect with remaining locations in your CMS.
Relying in your CMS, there could also be totally different options in place; for instance, you need to use this plugin for WordPress. In case you have a unique CMS, it’s possible you’ll want to make use of a customized resolution or ask your dev group to do it.
3. Use Server Aspect Rendering (HTML) At any time when Potential
Now, if we’re speaking about Google, its crawler makes use of the newest model of Chrome and is ready to see content loaded by JavaScript simply tremendous.
However let’s assume critically. What does that imply? Googlebot crawls a web page and sources akin to JavaScript then spends more computational resources to render them.
Keep in mind, computational prices are essential for Google, and it desires to cut back them as a lot as doable.
So why render content material through JavaScript (client side) and add further computational value for Google to crawl your pages?
Due to that, each time doable, it is best to persist with HTML.
That means, you’re not hurting your possibilities with any crawler.
4. Enhance Web page Pace
As we mentioned above, Googlebot crawls and renders pages with JavaScript, which suggests if it spends fewer sources to render webpages, the better it will likely be for it to crawl, which is determined by how nicely optimized your website speed is.
Google says:
Google’s crawling is proscribed by bandwidth, time, and availability of Googlebot situations. In case your server responds to requests faster, we’d be capable to crawl extra pages in your website.
So utilizing server-side rendering is already an awesome step in direction of bettering web page pace, however it’s good to be certain your Core Web Vital metrics are optimized, particularly server response time.
5. Take Care of Your Inner Hyperlinks
Google crawls URLs which are on the web page, and all the time remember the fact that totally different URLs are counted by crawlers as separate pages.
In case you have a web site with the ‘www’ model, be certain your inner URLs, particularly on navigation, level to the canonical version, i.e. with the ‘www’ model and vice versa.
One other frequent mistake is lacking a trailing slash. In case your URLs have a trailing slash on the finish, be certain your inner URLs even have it.
In any other case, pointless redirects, for instance, “https://www.instance.com/sample-page” to “https://www.instance.com/sample-page/” will end in two crawls per URL.
One other essential facet is to keep away from broken internal links pages, which may eat your crawl funds and soft 404 pages.
And if that wasn’t unhealthy sufficient, additionally they harm your person expertise!
On this case, once more, I’m in favor of utilizing a device for web site audit.
WebSite Auditor, Screaming Frog, Lumar or Oncrawl, and SE Rating are examples of nice tools for a website audit.
6. Replace Your Sitemap
As soon as once more, it’s an actual win-win to care for your XML sitemap.
The bots can have a a lot better and simpler time understanding the place the inner hyperlinks lead.
Use solely the URLs which are canonical in your sitemap.
Additionally, make it possible for it corresponds to the most recent uploaded model of robots.txt and masses quick.
7. Implement 304 Standing Code
When crawling a URL, Googlebot sends a date through the “If-Modified-Since” header, which is extra details about the final time it crawled the given URL.
In case your webpage hasn’t modified since then (laid out in “If-Modified-Since“), it’s possible you’ll return the “304 Not Modified” status code with no response physique. This tells serps that webpage content material didn’t change, and Googlebot can use the model from the final go to it has on the file.
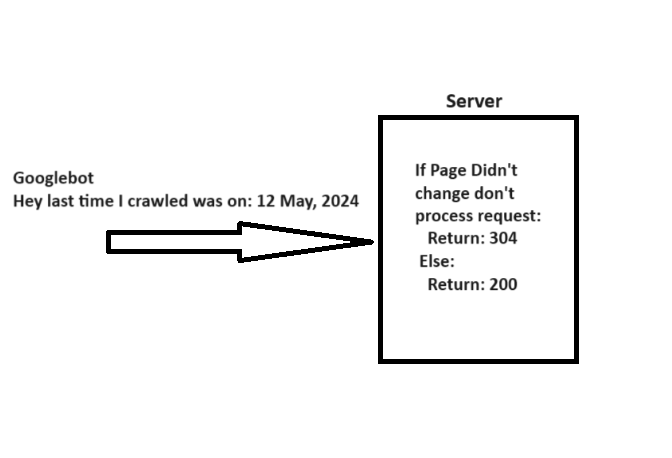 A easy rationalization of how 304 not modified http standing code works.
A easy rationalization of how 304 not modified http standing code works.Think about what number of server sources it can save you whereas serving to Googlebot save sources when you’ve hundreds of thousands of webpages. Fairly huge, isn’t it?
Nevertheless, there’s a caveat when implementing 304 standing code, pointed out by Gary Illyes.
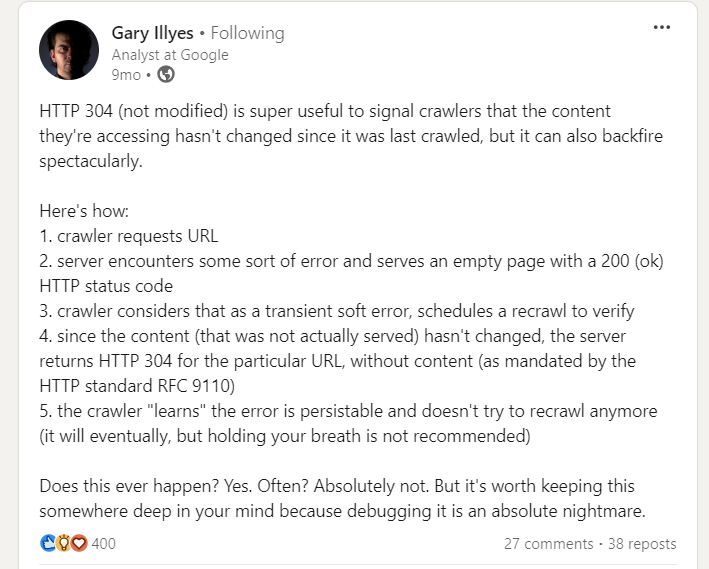 Gary Illes on LinkedIn
Gary Illes on LinkedInSo be cautious. Server errors serving empty pages with a 200 standing may cause crawlers to cease recrawling, resulting in long-lasting indexing points.
8. Hreflang Tags Are Very important
As a way to analyze your localized pages, crawlers make use of hreflang tags. You have to be telling Google about localized variations of your pages as clearly as doable.
First off, use the <hyperlink rel="alternate" hreflang="lang_code" href="https://www.searchenginejournal.com/technical-seo/tips-to-optimize-crawl-budget-for-seo/url_of_page" /> in your web page’s header. The place “lang_code” is a code for a supported language.
You need to use the <loc> factor for any given URL. That means, you’ll be able to level to the localized variations of a web page.
Learn: 6 Common Hreflang Tag Mistakes Sabotaging Your International SEO
9. Monitoring and Upkeep
Examine your server logs and Google Search Console’s Crawl Stats report to observe crawl anomalies and establish potential issues.
If you happen to discover periodic crawl spikes of 404 pages, in 99% of instances, it’s brought on by infinite crawl spaces, which now we have mentioned above, or signifies other problems your web site could also be experiencing.
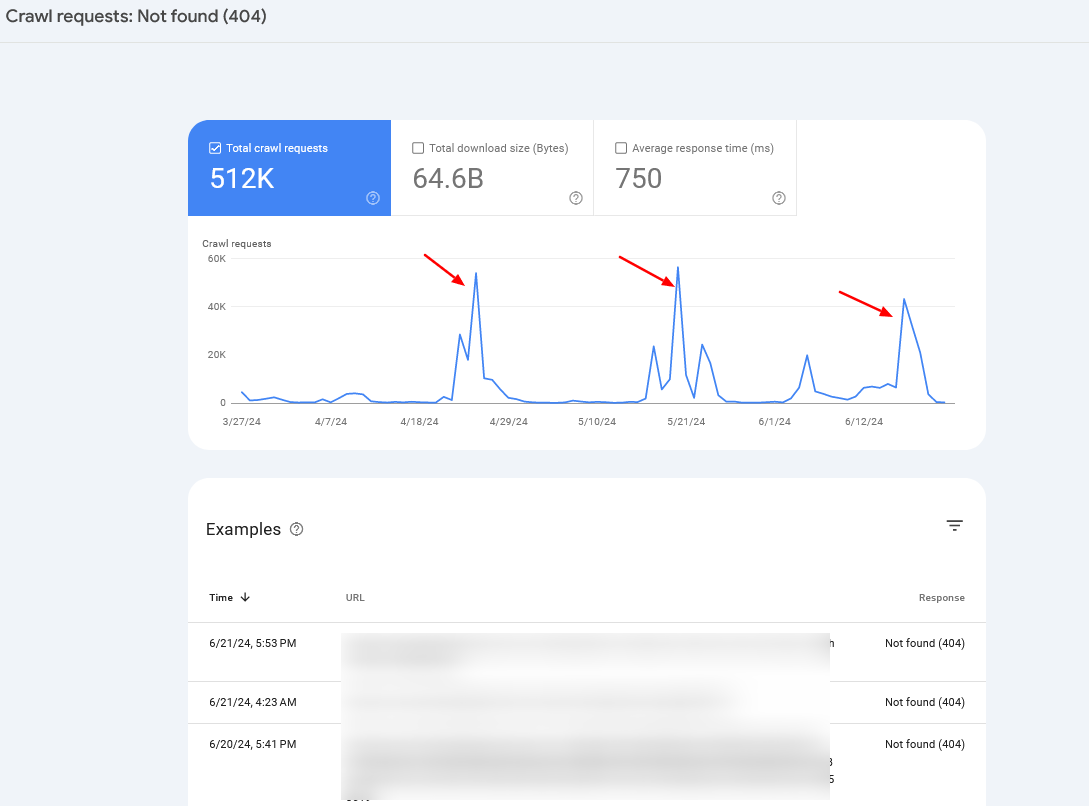 Crawl charge spikes
Crawl charge spikesUsually, it’s possible you’ll need to mix server log info with Search Console knowledge to establish the basis trigger.
Abstract
So, when you had been questioning whether or not crawl funds optimization continues to be essential in your web site, the reply is clearly sure.
Crawl funds is, was, and possibly will likely be an essential factor to remember for each web optimization skilled.
Hopefully, the following pointers will provide help to optimize your crawl funds and enhance your web optimization efficiency – however keep in mind, getting your pages crawled doesn’t imply they are going to be listed.
In case you face indexation points, I counsel studying the next articles:
Featured Picture: BestForBest/Shutterstock
All screenshots taken by writer